Mettre l’IA au service du BIM, comme l’ambitionne le projet IASBIM, revient à s’interroger sur notre capacité à comprendre des données 3D complexes. En particulier, avant même de se focaliser sur les modélisations BIM en tant que telle, l’étude des nuages de points 3D apparaît fondamentale. Est-on capable de tirer de l’information sémantique de cette donnée ?
Cet article va permettre de poser quelques jalons importants relativement à cette question.
Structure géométrique des nuage de points
Avant même de s’intéresser à la question de la segmentation sémantique, i.e. comment affecter une classe à chaque point dans le nuage, la plupart des méthodes d’analyse des nuages de points évaluent d’abord l’organisation géométrique des points. Plutôt que de déterminer si des points appartiennent au sol (respectivement aux murs), peut-on savoir s’ils constituent une surface plane horizontale (respectivement verticale) ?
La réponse à cette première question est amenée par deux analyses complémentaires :
-
le découpage du nuage de points en une structure hiérarchique, permettant de déduire efficacement des voisinages locaux (e.g.
KD-Tree,octree, …) ; -
des Analyses en Composante Principale visant à connaître la structuration générale d’un agrégat de points voisins, via les valeurs propres.
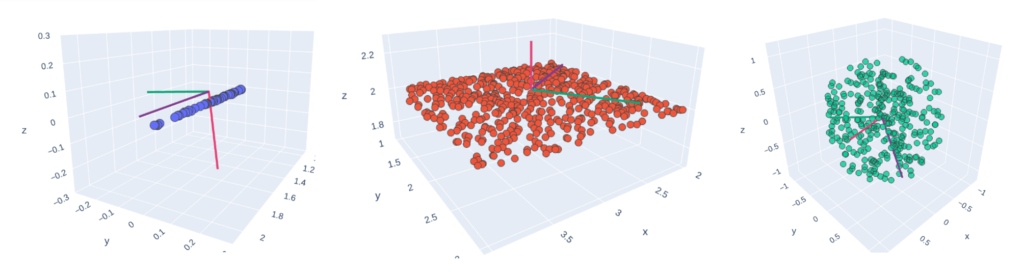
Cette procédure en deux étapes permet ainsi d’extraire des caractéristiques géométriques propres à chaque point du nuage ! Celles-ci sont extrêmement liées aux normales du nuage de points.
Segmentation sémantique simple
À ce stade, nous avons un nuage de points, représenté par des coordonnées x, y et z, ainsi
qu’un ensemble de caractéristiques tirées des analyses en composantes principales. Cela ouvre
naturellement la voie à l’application des méthodes du machine learning ! L’ensemble des
caractéristiques du nuage de points joue le rôle des variables explicatives, alors que la
classe sémantique associée à chaque point est la variable expliquée.
Deux possibilités existent alors :
-
le modélisateur a accès à des nuages de points labellisés, et donc, in fine à la valeur de la classe sémantique, pour au moins une partie de son nuage de point : dans ce cas, il s’agit de mettre en oeuvre un algorithme d’apprentissage supervisé, pour répondre à un problème de classification, par exemple une régression logistique, ou une Random Forest.
-
la donnée à laquelle le modélisateur a accès n’est pas labellisée : ici, on cherchera à déterminer une classe sémantique sans connaissance a priori, via un algorithme d’apprentissage non-supervisé, pour répondre à un problème de clustering (via l’algorithme des K-means).
Cette démarche a été précédemment entreprise par Oslandia dans le cadre du challenge Univers, un précédent projet de R&D mené avec l’entreprise Géolithe qui a abouti à la publication de la bibliothèque Python geo3dfeatures.
Segmentation sémantique et réseaux de neurones
Cependant, les résultats de ce type d’approche peuvent être largement améliorés en exploitant les réseaux de neurones ! Cette gamme d’algorithme a déjà révolutionné plusieurs domaines de recherche depuis une grosse dizaine d’années, et le traitement des données 3D n’échappe pas à la règle.
Relativement au cas d’usage du BIM, le jeu de données de l’état de l’art le plus pertinent est
S3DIS. Produit par l’université de Stanford,
il met en scène des captures 3D indoor, et a été abondamment utilisé dans la conception de
réseaux de neurones construits pour la segmentation sémantique des nuages de points.

La plupart des méthodes s’intéressent à un apprentissage supervisé de la donnée. L’état de l’art dans ce domaine de recherche est très dynamique depuis quelques années, si bien que plusieurs familles de modèles ont émergé :
-
Les premières tentatives ont consisté à discrétiser l’espace 3D via l’étude des voxels, comme structure atomique semblable aux pixels 2D. Dans cette approche, le nuage de points est converti en une structure régulière propice à l’application des réseaux de neurones convolutionnels. Cependant, le caractère irrégulier des nuages de points rend cette première catégorie d’algorithme plutôt inefficiente.
-
D’autres approches ont cherché à projeter la donnée 3D dans des espaces 2D, pour appliquer des réseaux de neurones convolutionnels aux images ; exercice déjà bien maîtrisé dans l’état de l’art de la segmentation sémantique. Cette seconde famille nécessite de bien définir les phases de translation entre 3D et 2D, et réciproquement.
-
La véritable rupture dans ce champ de recherche vient des premiers algorithmes appliquant directement des réseaux de neurones aux points en tant que tel. Uniquement à partir des coordonnées, ou en incluant quelques caractéristiques géométriques supplémentaires tirées des valeurs propres, ces méthodes ont longtemps été limitées par leur capacité à extraire des informations contextuelles des nuages de points (en particulier, en considérant les voisinages locaux de chaque point du nuage). Cependant, elles constituent des méthodes de référence souvent prises en exemple (notamment les modèles
PointNetetPointNet++). -
Parmi les méthodes les plus efficaces figure l’algorithme
KPConv, qui parvient à construire une opération de convolution directement appliquée à des nuages de points. La clé réside dans la définition d’un noyau de convolution défini comme un mini-nuage de points qui est combiné localement à un agrégat de points voisins. De façon générale, cela confirme la capacité de l’opération de convolution à extraire de l’information sémantique, comme dans le cas de la 2D.
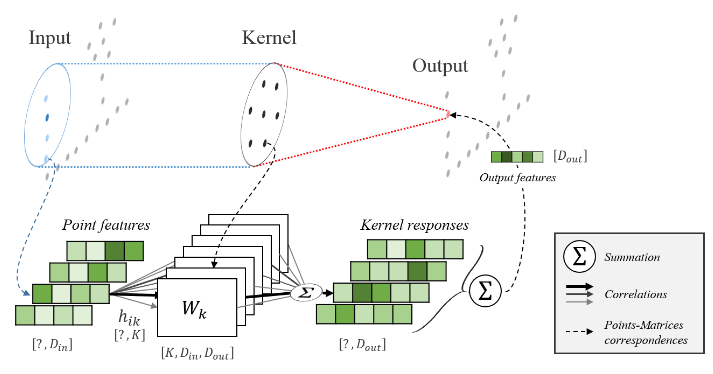
- Des techniques de modélisation encore plus récentes ont dernièrement été appliquées aux nuages de
points : le modèle
PointTransformerfait appel aux Transformers, tandis que le modèlePointMixerrepose sur des couches de mixage entre voisinages de points. Ces méthodes prometteuses pourraient constituer une alternative de choix à la famille des méthodes convolutionnelles.
Dans l’ensemble, l’exploitation de ces différentes méthodes est rendue plus facile par une très bonne disponibilité des principaux algorithmes sur la plateforme Github.
Et en l’absence de données labellisées ? L’application de toutes ces méthodes devient impossible, mais des alternatives existent…! Ainsi, le concept de Weak Supervision est une piste particulièrement prometteuse pour ce cas de figure : une bonne connaissance métier permettrait ainsi de définir des fonctions de coût pertinentes pour matérialiser un défaut de données annotées. Connaître les classes d’une petite partie seulement d’un nuage de points pourrait ne pas être un frein, mais le challenge technique est ici de taille !
Aller plus loin que les nuages de points
Cet article démontre la richesse de l’état de l’art technique pour la segmentation sémantique des nuages de points 3D. Cela pourra constituer un premier axe de travail particulièrement riche pour le projet IASBIM.
Cependant, l’objectif du projet ne se limite pas à cette problématique ! Extraire de l’information sémantique des nuages de points (via des méthodes simples…ou par le biais d’un réseau de neurones) pourra certes constituer un input décisif pour la suite du projet, consacrée à la modélisation BIM. Mais d’autres questions demeurent, à ce stade.
Comment reconstruire des volumes à partir des nuages de points, comment appliquer l’opération de segmentation sur les volumes géométriques, et in fine, comment générer un modèle BIM semantisé ? La suite du projet IASBIM devrait être riche en enseignement relativement à ces interrogations !